Genomic Analysis
From complex raw data to publication-ready results
Why Genomic Data Analysis Matters
Think of your genome as the ultimate instruction manual for life. It holds answers to some of the biggest questions in biology, medicine, agriculture, and biotechnology. The problem? Sequencing machines can now generate millions, even billions, of data points in just one run. And without the right tools or expertise, all that data is like a locked treasure chest, full of insights but nearly impossible to open.
That’s where genomic data analysis comes in. By using advanced bioinformatics pipelines, statistics, and smart computational methods, we can turn raw sequencing data into clear, meaningful insights. It’s the difference between staring at endless lines of code and actually understanding the story your DNA is trying to tell.
What We Can Do For You
At The Freelance Bubble, we make this process simple and practical. We don’t just hand you complicated graphs and jargon, we help you understand what your data actually means. Whether you’re trying to figure out how a mutation impacts cancer progression, exploring how plants survive under stress, diving into microbial communities, or working on personalized medicine, we’ve got you covered.
We know that as a researcher, your time is limited and every dataset feels urgent. That’s why we focus on delivering insights you can actually use, not just raw numbers. From guiding your next experiment to helping you prepare publication-ready figures, we make sure your data works for you instead of slowing you down.
Request A Consultation

Raw Data Processing & Quality Control (QC)
We ensure your raw sequencing data is clean, reliable, and ready for downstream analysis.
Services include:
- Quality assessment of raw reads (FastQC, MultiQC)
- Adapter trimming and low-quality read removal (Trimmomatic, Cutadapt)
- Removal of contaminant sequences (host/microbial filtering)
- Read alignment to reference genomes (BWA, Bowtie2, STAR, HISAT2)
- Generation of QC reports for publication
Genome Assembly & Annotation
We reconstruct genomes from raw reads and provide detailed gene annotations.
Services include:
- De novo genome assembly (SPAdes, Canu, Flye for Illumina/Nanopore/PacBio)
- Hybrid assemblies combining short- and long-read data
- Scaffolding, gap-filling, and assembly polishing (Pilon, Racon, Medaka)
- Automated genome annotation (Prokka, MAKER, NCBI pipelines)
- Identification of coding genes, rRNAs, tRNAs, and regulatory elements
Variant Analysis
Identify genetic variations linked to phenotypes, diseases, or evolutionary traits.
Services include:
- SNP and Indel calling (GATK, FreeBayes, Samtools)
- Structural variant detection (Manta, LUMPY, Delly)
- Copy number variation (CNV) analysis (CNVnator, Control-FREEC)
- Variant annotation (ANNOVAR, SnpEff, Ensembl VEP)
- Functional effect prediction on coding/non-coding regions
Comparative Genomics
Uncover similarities and differences across genomes to study evolution, function, and diversity.
Services include:
- Pan-genome construction and analysis (Roary, BPGA, Panaroo)
- Ortholog and paralog detection (OrthoFinder)
- Genome synteny analysis and structural comparisons
- Core, accessory, and unique gene identification
- Phylogenomic tree construction (RAxML, IQ-TREE, PhyML)
Population Genomics
Explore population structure, diversity, and evolutionary dynamics.
Services include:
- Population structure analysis (PCA, STRUCTURE, ADMIXTURE)
- Genetic diversity metrics (π, FST, Tajima’s D, heterozygosity)
- Haplotype phasing and linkage disequilibrium analysis
- Genome-wide association studies (GWAS)
- Demographic history and selective sweep analysis
Functional Genomics
Link genes and variants to biological pathways and molecular functions.
Services include:
- Gene Ontology (GO) enrichment analysis
- Pathway mapping and enrichment (KEGG, Reactome, BioCyc)
- Identification of regulatory elements (promoters, enhancers, TF binding motifs)
- Integration with transcriptomics/proteomics datasets
Manuscript Writing & Publication Support
We help you move from raw data to publishable scientific outputs.
Services include:
- Custom NGS pipelines tailored to project needs
- Multi-omics data integration (genomics + transcriptomics + proteomics + metabolomics)
- Advanced visualization (Circos plots, Manhattan plots, heatmaps, phylogenetic trees, pathway maps)
- Preparation of publication-ready figures, supplementary tables, and methods section drafts
Mentorship & Trainings



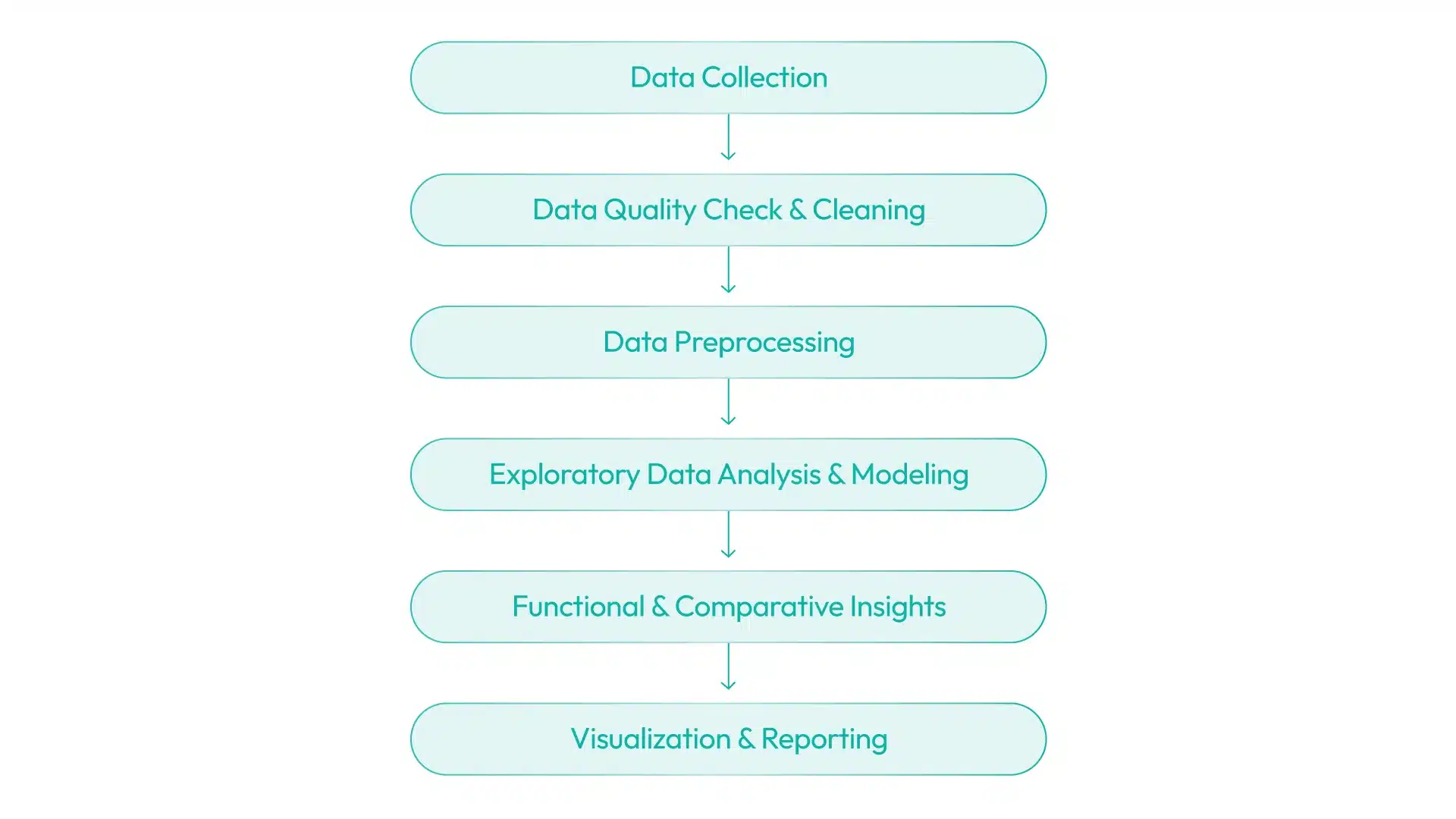
Our 4 Step Workflow
Most Frequently Asked Questions (FAQs)
We work with a wide range of biological data, including sequencing (RNA-Seq, ChIP-Seq, WGS), proteomics, genomics, and clinical datasets.
Both work! We can handle raw sequencing data (FASTQ) as well as pre-processed formats depending on your project stage.
Timelines vary by complexity, but most projects are completed within 1–3 weeks. Urgent analyses can be prioritized.
Yes — we provide clear visualizations, detailed results, and easy-to-follow interpretations tailored for publications or research presentations.
Absolutely. Every project is customized — from choosing the right tools to designing workflows that match your study goals.
Yes — we can format results, prepare figures, and support manuscript writing to strengthen your research output.
Ready to bring your vision to life? Let’s schedule a Free Consultation and explore how we can make your project a success!